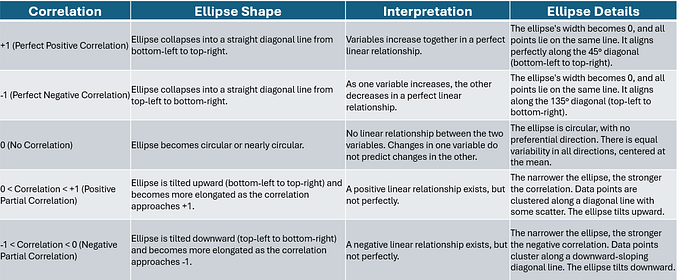
Unveiling the Power of Embedded Methods in Machine Learning: A Deep Dive into Embedded Feature Selection Methods
Machine learning is a dynamic field that has transformed our approach to problem-solving across various domains. At the heart of creating powerful machine learning models lies the art of feature selection. Embedded feature selection methods, often overshadowed by their filter and wrapper counterparts, are a remarkable set of techniques that seamlessly integrate feature selection into the model training process. In this article, we will embark on a journey to understand the significance of embedded methods in machine learning, explore their practical applications, and learn how to implement them.
Why Feature Selection Matters
Feature selection is the process of choosing a subset of relevant features from a larger pool of variables or attributes. It is essential because it can significantly impact the performance of machine learning models. Selecting the right features:
- Enhances Model Efficiency: Reducing the dimensionality of the dataset by selecting only the most relevant features can lead to faster training and prediction times.
- Mitigates Overfitting: By focusing on critical information, feature selection helps prevent the model from learning noise in the data, leading to better generalization.
- Improves Model Interpretability: Models built on a concise set of features are easier to understand and interpret, which is crucial for decision-making and model transparency.
Embedded Methods: A Brief Overview

Embedded methods are a category of feature selection techniques that are tightly integrated into the model training process. Unlike filter methods (which perform feature selection independently of the model) and wrapper methods (which use a specific algorithm for evaluation), embedded methods incorporate feature selection directly into the model’s
Embedded methods for feature selection are a family of techniques that incorporate feature selection directly into the model training process. Unlike filter methods, which independently evaluate features, or wrapper methods, which use specific models for evaluation, embedded methods are an integral part of the model optimization process. They work by evaluating feature relevance while the model is being trained and can lead to improved model performance and generalization.
Embedded methods are highly effective in various scenarios, such as when you have a high-dimensional dataset with many features, and you want the model to automatically select the most informative ones. These methods strike a balance between the simplicity of filter methods and the computational cost of wrapper methods.
Let’s explore some common embedded feature selection methods in more detail:
L1 Regularization (Lasso): L1 regularization, commonly known as Lasso (Least Absolute Shrinkage and Selection Operator), is a powerful technique for feature selection. It introduces a penalty term to the loss function during model training, encouraging the model to set some feature weights to zero. This effectively selects a subset of the most important features. Here is an implementation example:
import numpy as np
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LassoCV
from sklearn.model_selection import train_test_split
# Load a sample dataset (Diabetes dataset)
data = load_diabetes()
X, y = data.data, data.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create a LassoCV model with cross-validation
lasso_cv = LassoCV(alphas=np.logspace(-4, 4, 100), cv=5)
lasso_cv.fit(X_train, y_train)
# Print the selected alpha (regularization strength)
print(f"Selected alpha: {lasso_cv.alpha_}")
# Get the coefficients and selected features
lasso_coefs = lasso_cv.coef_
selected_features = np.where(lasso_coefs != 0)[0]
print("Selected Features:")
for feature in selected_features:
print(data.feature_names[feature])
# Evaluate the model on the test set
lasso_score = lasso_cv.score(X_test, y_test)
print(f"Model R-squared score on test data: {lasso_score}")Tree-Based Methods (Random Forest): Tree-based methods like Random Forest have embedded feature selection capabilities. They calculate feature importance during the construction of decision trees, and features with higher importance are considered more influential. Here is an implementation example:
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# Load a sample dataset (Iris dataset)
data = load_iris()
X, y = data.data, data.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create a Random Forest classifier
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
rf_classifier.fit(X_train, y_train)
# Get feature importances
feature_importances = rf_classifier.feature_importances_
# Print feature importances
print("Feature Importances:")
for i, importance in enumerate(feature_importances):
print(f"Feature {i}: {importance}")
# Select the most important features
selected_features = np.argsort(feature_importances)[::-1][:2]
print("Selected Features:")
for feature in selected_features:
print(data.feature_names[feature])
# Evaluate the model on the test set
rf_accuracy = rf_classifier.score(X_test, y_test)
print(f"Model accuracy on test data: {rf_accuracy}")Elastic Net: Elastic Net is a regularization technique that combines L1 (Lasso) and L2 (Ridge) regularization. It strikes a balance between feature selection and feature grouping. In this method, the loss function consists of both L1 and L2 penalty terms. Here is an implementation example:
from sklearn.linear_model import ElasticNetCV
# Create an Elastic Net model with cross-validation
elastic_net = ElasticNetCV(alphas=[0.01, 0.1, 1.0, 10.0], l1_ratio=[0.1, 0.5, 0.7, 0.9], cv=5)
elastic_net.fit(X_train, y_train)
# Get the selected alpha and corresponding coefficients
selected_alpha = elastic_net.alpha_
selected_features = data.feature_names[np.where(elastic_net.coef_ != 0)]
print(f"Selected alpha: {selected_alpha}")
print(f"Selected features: {selected_features}")Recursive Feature Elimination (RFE): Recursive Feature Elimination is an iterative embedded method that starts with all features and successively removes the least important ones based on model performance. It continues this process until a specified number of features or a predefined performance threshold is reached. RFE is particularly valuable when you have a high-dimensional dataset, and you want to iteratively simplify your model by removing less informative features. Here is an implementation example:
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
# Create a base model (e.g., Linear Regression)
base_model = LinearRegression()
# Create an RFE model with the base model
rfe = RFE(estimator=base_model, n_features_to_select=5)
rfe.fit(X_train, y_train)
# Get the selected features
selected_features = data.feature_names[rfe.support_]
print(f"Selected features: {selected_features}")Regularized Linear Models: Various linear models like Ridge Regression and Logistic Regression can be regularized using L1 or L2 regularization techniques. These regularization terms help with feature selection. Ridge Regression (L2 Regularization): Adds an L2 penalty term to the loss function, which encourages feature weights to be small but doesn’t force them to zero. This helps to select important features while keeping all features in the model. Logistic Regression (L1 Regularization): Similar to Lasso, it adds an L1 penalty to the logistic regression loss function, leading to feature selection. Here is an implementation example:
from sklearn.linear_model import RidgeCV
# Create a Ridge Regression model with cross-validation
ridge = RidgeCV(alphas=[0.01, 0.1, 1.0, 10.0], cv=5)
ridge.fit(X_train, y_train)
# Get the selected alpha and corresponding coefficients
selected_alpha = ridge.alpha_
selected_features = data.feature_names
print(f"Selected alpha: {selected_alpha}")
print(f"Selected features: {selected_features}")Each of these embedded methods provides different tools and strategies for feature selection in machine learning. The choice of method depends on your dataset, problem, and goals. They are invaluable for improving model efficiency, interpretability, and generalization by selecting the most relevant features for your specific task.
Real-World Applications
Embedded methods find applications in various domains and industries:
- Medical Diagnosis: Identifying crucial features in medical datasets can help in the early detection of diseases and improve patient care.
- Finance: In finance, embedded methods can uncover relevant market indicators for predicting stock prices or identifying fraudulent transactions.
- Natural Language Processing (NLP): Feature selection in NLP can help filter out irrelevant words and improve the accuracy of sentiment analysis or text classification models.
- Image Analysis: In computer vision, embedded methods can identify significant image features for tasks like object recognition and facial expression analysis.
- Manufacturing: Embedded methods can be used to identify essential parameters in manufacturing processes to optimize production and reduce defects.
Conclusion
Embedded methods in machine learning offer a powerful solution to the challenge of feature selection. They allow models to identify and utilize the most informative attributes, leading to improved efficiency, reduced overfitting, and enhanced interpretability. As machine learning continues to permeate various industries and applications, understanding and harnessing the capabilities of embedded methods will be crucial for building effective and reliable predictive models. By doing so, we can unlock the full potential of machine learning to solve complex real-world problems.